Module d’Analyse Statistique :
Introduction générale
M1 Géomatique - M2 IGAST
Martin Cubaud
LASTIG-UGE-IGN/Géodata Paris
2025-2026
Introduction générale
Réferences
- Cours M2 IGAST 2021 de Paul Chapron et 2018 d’Ana-Maria Olteanu-Raimond
- Probabilités, analyse de données et statistiques , Gilbert Saporta, Editions TECHNIP, 2011
- Cours de H. Commenges
- Nombreuses ressources en ligne, e.g. :
- http://www.foad-mooc.auf.org/IMG/pdf/424B_-Application_des_methodes_statistiques_d_analyse.pdf
- http://www.itse.be/statistique2010/co/Module_statistique_FSP.html
Analyse spatiale : définition
L'analyse spatiale étudie la répartition et l'organisation d'ensembles d'objets qui sont localisés.
L'objectif est de :
"déceler en quoi la localisation apporte un élément utile à la connaissances des objets étudiés et peut en expliquer les caractéristiques"
[Pumain, Saint-Julien 97]
Specifité de l'analyse spatiale
Analyse statistique :
Méthodes résumant et généralisant des observations
- Les unités d'analyse sont des éléments indépendants en principe
- On ne s'intéresse pas à leur localisation ni à leurs intéractions (spatiales)
Analyse spatiale statistique :
- Les unités d’analyse sont localisables
- On s’intéresse à leur propriétés y compris la localisation
- On fait l’hypothèse que leur localisation peut influencer les valeurs observées
Données spatiales vs. non spatiales
Données spatiales :
Individus restreints spatialement (selection spatiale), ou variables de localisation géographique (e.g. Lieu de résidence, coordonnées) renseignées pour les individus
Quid des distances ? → modèle gravitaire, réseau etc.
Deux approches
Analyse géométrique :
Approche géométrique pour mieux décrire les données: analyse de forme, de réseaux, de proximité, méthodes de création de nouvelles entités à partir de la géométrie des objets.
Analyse de données :
Approche statistique permettant de faire émerger des relations (des groupes, des lois) pour aider l'étude de certains phénomènes.
Statistiques Inférentielles
vs
Statistiques Descriptives
Statistiques Inférentielles
A partir d’un échantillon , que peut-on attendre (=inférer) de la population ?
- Modèles, estimateurs... : régression, estimation, extrapolation
- e.g. sondages, recensement...
Statistiques Inférentielles : exemple
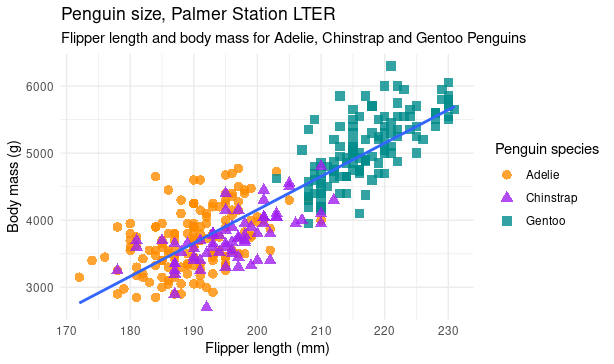
Penguins data were collected and made available by Dr. Kristen Gorman and the Palmer Station, Antarctica LTER, a member of the Long Term Ecological Research Network.
[https://github.com/allisonhorst/palmerpenguins]Statistiques Descriptives
Décrire, résumer, synthétiser les propriétés d'une population à partir des variables qui décrivent ses individus.
- Graphiques : nuages de points, histogramme...
- Mesures (fréquences, distributions, moments) sur des variables
- Liaisons statistiques entre variables : corrélation, covariance...
- Structure interne des données : classification, ACP...
Attention aux groupes ! (paradoxe de Simpsons)
Paradoxe de Simpsons
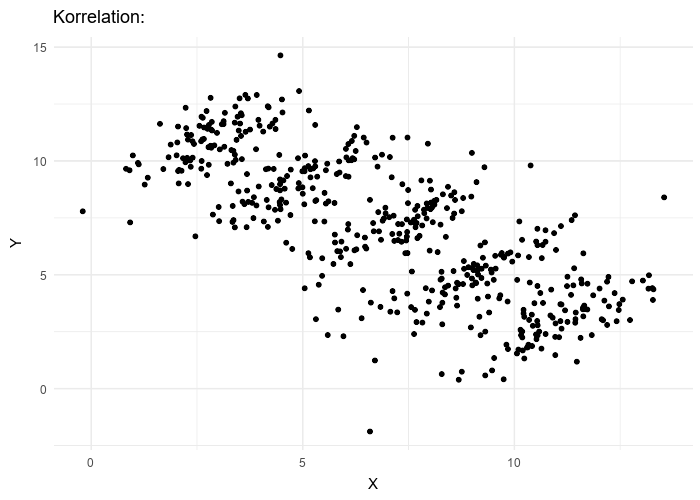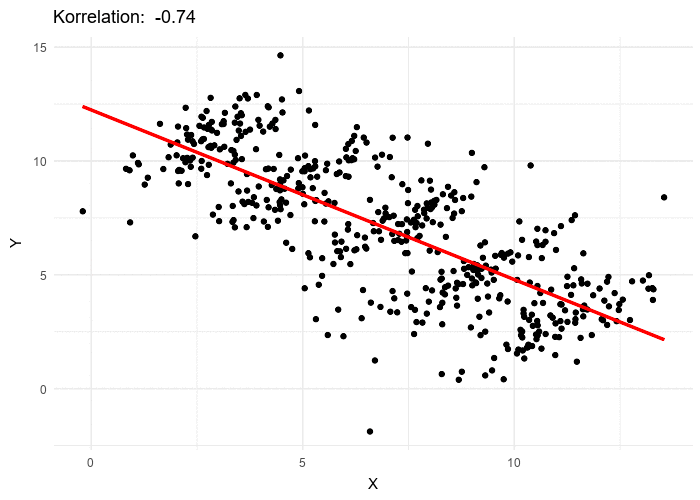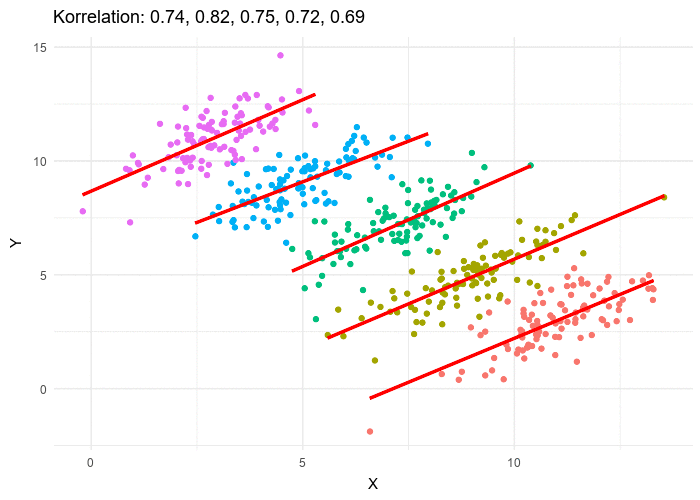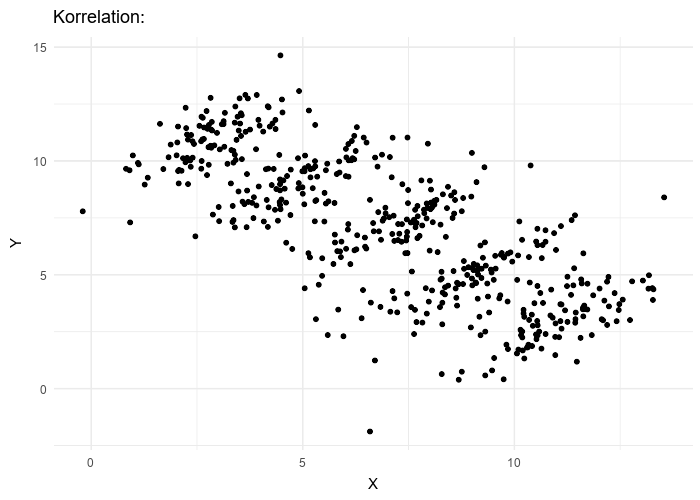
Dans ce module
Nous ferons majoritairement de la statistique descriptive
(Même si, pour bien décrire, il faut parfois inférer).
Vocabulaire
Population
Ensemble d'individus
"données", "corpus", "échantillon", "data"
Très souvent tabulaires
Individu
Unité statistique élémentaire : personnes, logements...
→ "les lignes du tableau"
Variables
Caractéristiques, propriétés d'un individu, mesurées par des enquêtes, des observations...
→ "les colonnes du tableau"
Types de variables
Qualitatives : facteurs e.g. couleur, genre, CSP, type de pokemon... → notion de modalité
Quantitatives : nombres e.g. taille, masse, revenu, surface, points de vie... parfois exprimés avec des unités : m, kg, s
Discrètes et Continues
Variables quantitatives continues : $var \in \R $
Valeurs réelles, toutes les valeurs de l'intervalle de mesures peuvent exister
Variables quantitatives discrètes : $var \in \N $
Valeurs entières, pour des attributs dénombrables (comptage)
parfois utilisées pour encoder une variable qualitative à deux modalités e.g. présence (1), absence (0)
Variables qualitatives
Les valeurs sont prises dans un ensemble fini de valeurs possibles, défini par extension (i.e. on donne la liste des valeurs possibles)
→ notion de modalités
→ nominales (non ordonnées ex état civil) ou
→ ordinales (ordonnées ex échelle de Likert)
L'échelle d'Analyse
Spécificité de la statistique spatiale : à quelle échelle observer ?
Quel découpage, quelles unités spatiales ?
"Problème insoluble" : le MAUP (Modifiable Areal Unit Problem)
Unités spatiales
Mailles administratives :
agrégation/imbrication d’unités spatiales prédéfinies : comtés, départements, régions, pays...
e.g. Comprendre comment le taux de chômage d'un pays est distribué entre les régions pour guider les politiques économiques
Découpages :
identification d'unités spatiales ayant des catactéristiques semblables
e.g. IRIS, carroyage
échelle individuelle vs echelle agrégée
Désagrégation ou Ventilation :
→ Inférer des caractéristiques individuelles à partir de l'analyse de données agrégées (ni facile ni immédiat)
Agrégation :
→ Inférer des caractéristiques concernant les unités agrégés d'après les caractéristiques individuelles
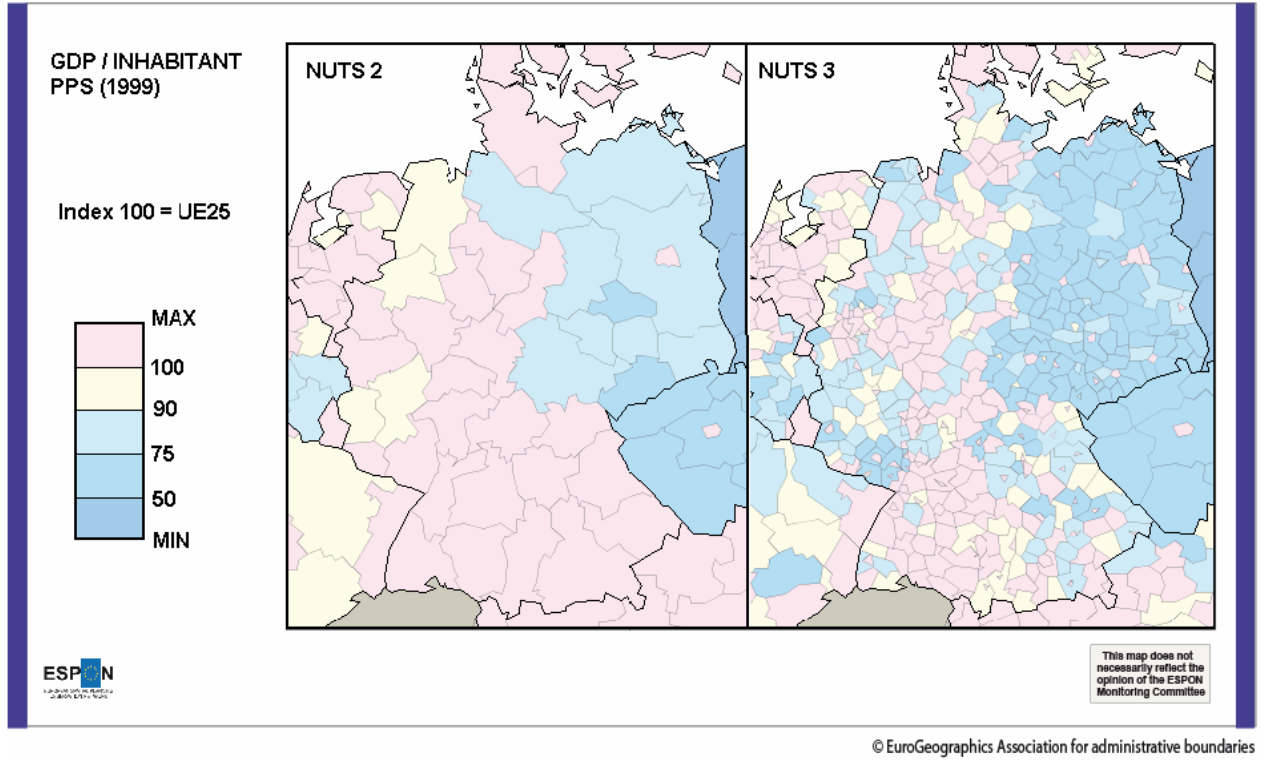
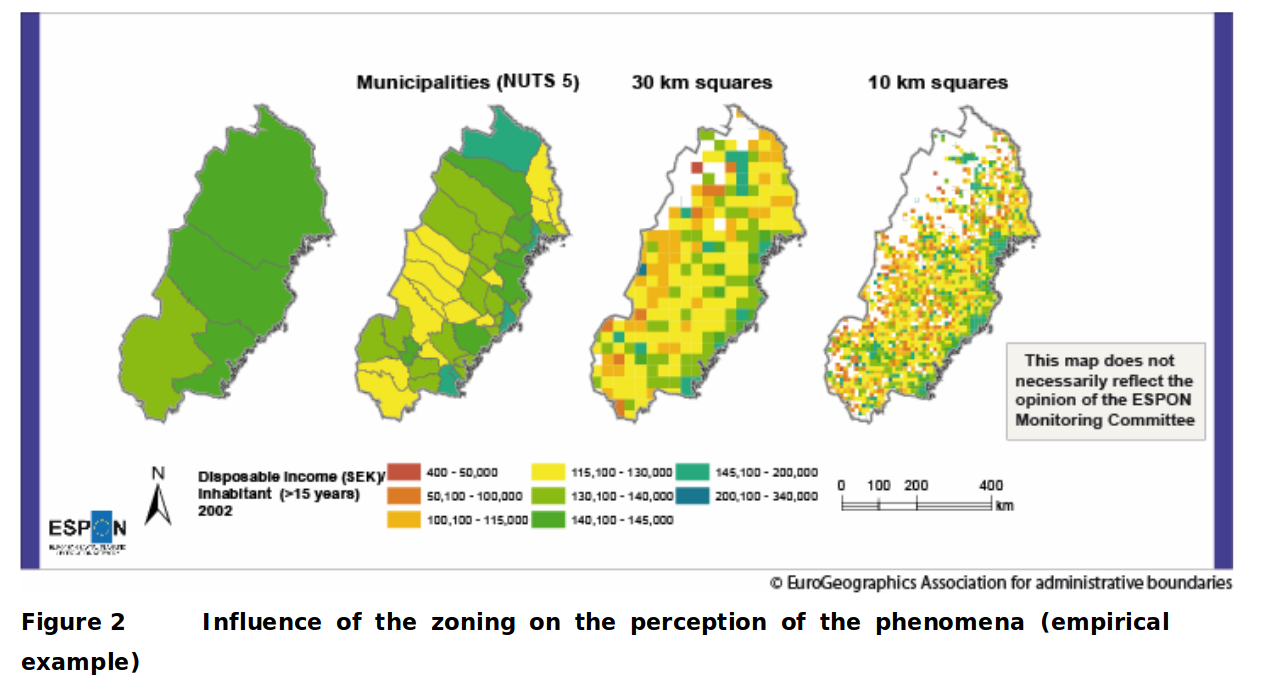
le MAUP (Modifiable Areal Unit Problem)
Problème d'agrégation spatiale : les résultats d'une analyse statistique spatiale dépendent du choix d'agrégation
→ biais "systématique et insoluble"
Exemples tirés du rapport ESPON :
https://www.espon.eu/sites/default/files/attachments/espon343_maup_final_version2_nov_2006.pdfMAUP exemple 1
MAUP exemple 2
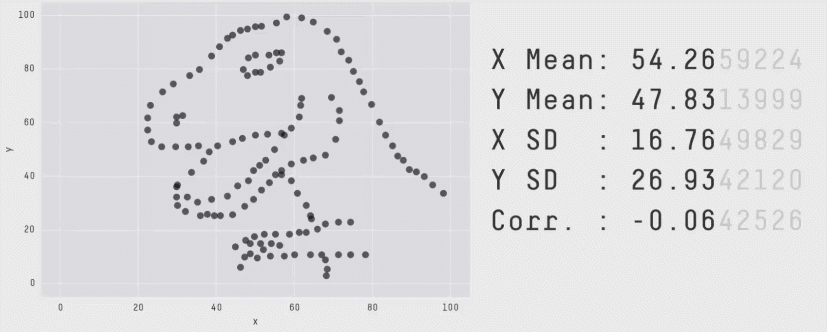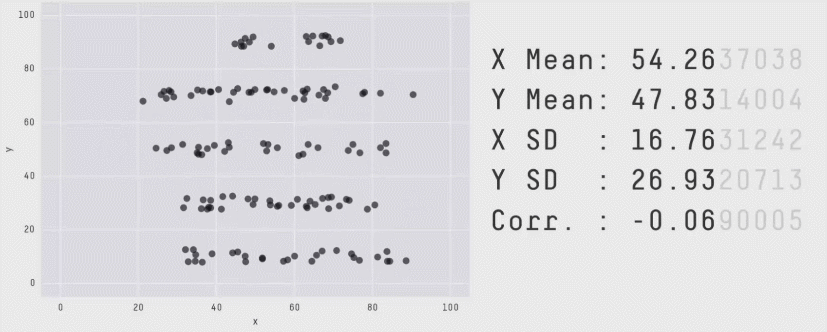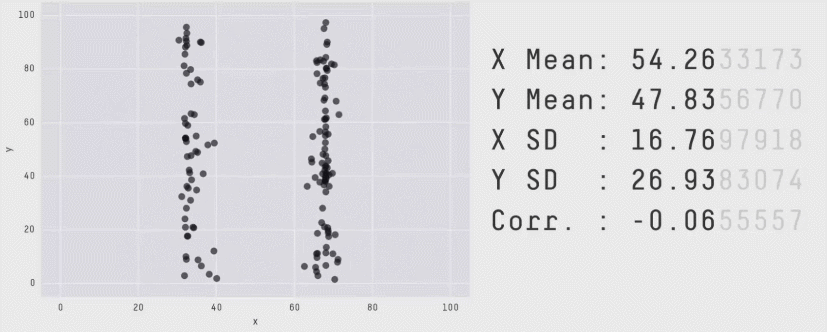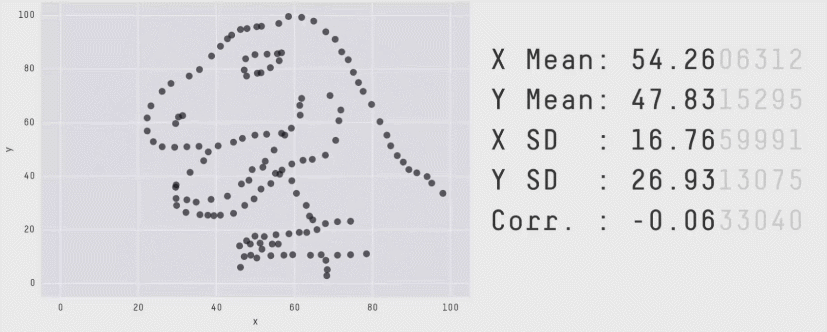
Attention aux seules valeurs chiffrées !
La première "chose à faire" !
Pandas ?
Librairie python pour manipuler, explorer, visualiser, nettoyer, traiter... intuitivement des données tabulaires :

Importer Pandas
import numpy as np
import pandas as pd
Deux structures de données de base dans Pandas (Classes Python)
- Series: Données unidimensionnelles de n'importe quel type
- DataFrame: Données tabulaires
Creation d'un Dataframe
df = pd.dataframe(data, index=index_names, columns=columns_names)
- df: la variable Python qui va contenir le dataframe.
- data: les données sous forme de tableau Python, de dictionnaire ou d'array de Numpy.
- index: (optionnel) la liste des indices des individus
- columns: (optionnel) la liste des noms des variables (statistiques)
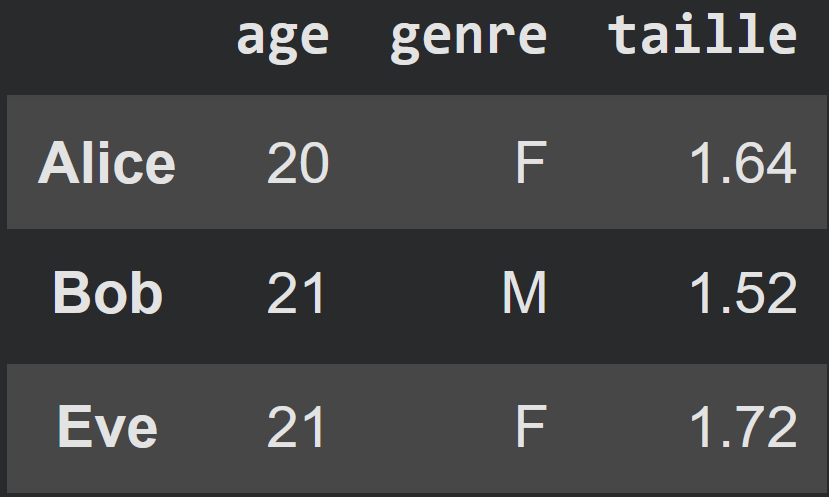
Exemple
data = [[20, "F", 1.64], [21, "M", 1.52], [21, "F", 1.72]]
names = ["Alice", "Bob", "Eve"]
variables = ["age", "genre", "taille"]
df = pd.DataFrame(data, columns=variables, index=names)
df
Lecture / Ecriture de données

Exemple : df = pd.read_csv("chemin/vers/le/fichier.csv")
Sélection d'un sous-ensemble des données

Toutes ces méthodes renvoient une nouvelle table, elles ne modifient pas df
Modifier l'age d'Alice : df.loc["Alice", "age"] = 21 (modifie vraiment df)
Modifier l'age de tout le monde : df.loc[:, "age"] = df.loc[:, "age"] + 1
Ajouts de nouvelles colonnes
df["envergure des bras"] = [1.60, 1.76, 1.74]
df["Indice Ape"] = df["envergure des bras"]/df["taille"]
df
| age | genre | taille | envergure des bras | Indice Ape | |
|---|---|---|---|---|---|
| Alice | 20 | F | 1.64 | 1.60 | 0.975610 |
| Bob | 21 | M | 1.52 | 1.76 | 1.157895 |
| Eve | 21 | F | 1.72 | 1.74 | 1.011628 |
Autres fonctionnalités
- Jointures (fusionner des tables)
- Groupements
- Aggrégation
- Méthodes statistiques
- Visualisation de données
- Transformations sur les lignes et les colonnes
- ...
Cas particulier des données géographiques
La librairie GeoPandas étend Pandas pour les données géographiques (vecteurs)
Lecture de divers formats de fichiers géospatialisés (shapefile, geojson...)
Colonne geometry qui stocke les unités spatiales (Shapely)
Opérations géométriques et topologiques